Color Pickers
(Originally published on November 29, 2009)
I bet you've seen color pickers before. They are neat UI elements that allow you to select a particular color that you may have in mind. They do that by organizing the entire color space in a way that's easily browsed. Usually, pickers show you a 2D panel that displays all colors along two of the dimensions, and a slider for the third dimension; or they only show you a small-ish subset of all the colors.
I’m fascinated with color, especially when there’s math or technology involved. And so I set out to build a picker that displays all the colors, yet requires only a single two-dimensional surface.
The color space is three-dimensional: to uniquely identify a color, you have to specify three dimensions. There are many ways to specify a color: the most common one (albeit not the more natural one to understand) is the RGB space: each color is identified by the intensity of pure red, pure green and pure blue components that, when mixed together additively, construct the desired color. I emphasize additively because when we think about “mixing” color (when we paint with oil or watercolor) we don’t actually compose color the same way our eye does. In the RGB space, there are three numbers you specify for each color: and so yellow can be defined as (1.0, 1.0, 0.0) because it consists of max intensity red and green and no blue. Violet (like the color of this flower) can be defined as (0.6, 0.3, 0.7).
Similarly, there are other ways to describe a color: the HSL space, that I find fairly intuitive, describes a color by specifying its hue (the location on the rainbow), its saturation (how vibrant is the color) and lightness (how bright it is). Again, three dimensions (why the color space is three-dimensional is an interesting question…).
This fact makes it hard to design user interface elements that allow you to pick a color (color pickers): the screen is two-dimensional so you either need a slider or some other way to change the third dimension, or you will see a selection of all colors. Being a visual person, I wanted to have a picker that displays all the colors at once, without some stupid slider.
My first attempt took advantage of the fact that on a computer, every measure is discrete (there is no such thing as infinity in computing) so I can collapse the three dimensions into two simply by cleverly rearranging where each colors should be placed. Assuming that each color component has 256 degrees of intensity (which is the case in computer screens these days), we can list all colors, for example
(0, 0, 0), (0, 0, 1), …, (0, 0, 255),
(0, 1, 0), (0, 1, 1), …, (0, 1, 255),
…
(255, 255, 0), …, (255, 255, 255)
We can now map the sequence into a two-dimensional one, for example
(0, 0), (0, 1), …, (0, 4095),
(1, 0), (1, 1), …, (1, 4095),
…
(4095, 0), …, (4095, 4095)
The problem, however, is that we want the mapping to be smooth, i.e. ideally we would like nearby pixels to have similar colors, and the mapping above (and in fact most mappings) won’t guarantee this.
This is where math comes in handy, specifically the field of space-filling curves. I kept one dimension (say, the blue component)–that will be my X coordinate of the resulting picker. For the other, I used a Hilbert-like curve to collapse the green and red components into one Y coordinate. A nice thing about Hilbert curves is that they are somewhat smooth: in this picture, if you pick two neighboring points they are likely to be close to one another on the curve. I’ll leave as an exercise for the reader to determine the actual expected Euclidean distance in color intensity for randomly picked two neighboring points on a Hilbert curve.
Well, such was the first experiment. The resulting “color belt” was very long (because collapsing two dimensions into one makes it a very long dimension!) and the lack of smoothness was pretty obvious :
My first approach to create a two-dimensional complete color picker
I then took the belt and made it into a ring, by “curving” the long dimension around (to take advantage of the fact that the circumference gives me 2π more space than the radius:
The color ring
Besides looking very Tolkenian, the ring has a pleasing æsthetic to it. Still, it’s somewhat hard to pick out the color you want because the colors are fairly scattered (if your mouse if off by one pixel you may be picking a totally different color).
The next approach was to be a little smarter with the choice of dimensions. Instead of picking one of the components to be one dimension and try to collapse the other two, I chose the light intensity of a color as the horizontal dimension and then collapsed all colors of a given intensity into the vertical dimension. The advantage of this approach was an increased smoothness: all colors along a vertical line had the same intensity; and because the intensity function is linear in the values of R, G and B (it’s a weighted average of the red, green and blue intensity), the colors on a horizontal line are all similar.
I also varied the order in which colors would be placed on a vertical line, based on a heuristic of the R, G and B component. Some of the choices gave very interesting results. Some of these pickers are shown in the gallery below, in order:
- Image 1. Plotting each vertical line based on the lexicographical order (sort by R, then G, then B)
- Image 2. Making the heuristic slightly more complex: ordering the pixels by the value of the sum of squares of the colors
- Images 3 & 4. Bundling similar colors together (to have fewer “boundaries” where neighboring colors differ significantly at the expense of more pronounced boundaries): I used a heuristic that “favored” one component over another.
- Specifically, for Image 4: In first order, pixels whose B is higher than R appear higher in the image. Then pixels whose G is higher than B. Finally, pixels whose R is higher than their G
- Image 5. Pixels ordered by saturation - funky!



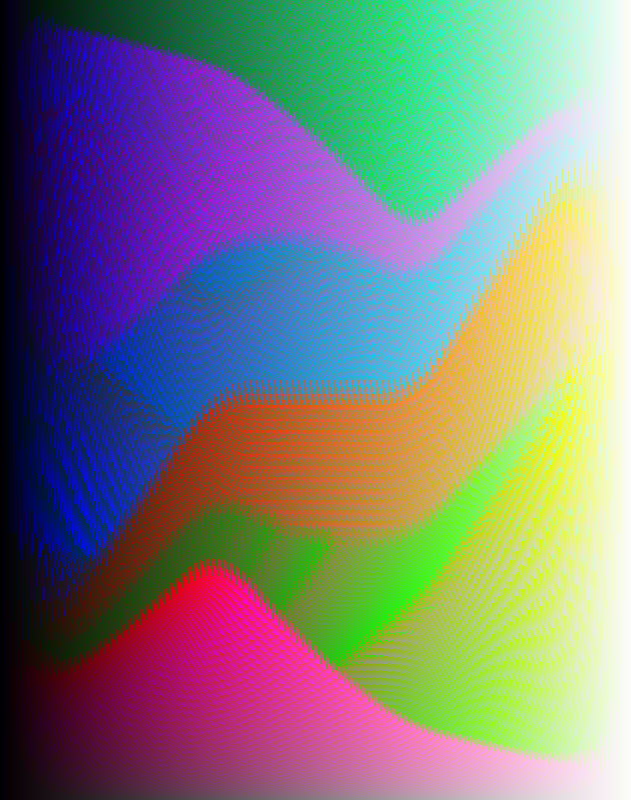

Finally, massaging one of the above pickers slightly (to eliminate some of the more obvious artifacts), reducing in size and despeckling (to make picking more accurate), and with a pure gray gradient on the side for easy reference, we get the complete yet two-dimensional color picker:

The final color picker
See also
Source code for the color belt and color ring generator – generates a PNG file, so redirect the stdout to a file, say output.png
References for a useful cheatsheet of color conversions
Layered color picker – it generates a PBM file that Photoshop/ImageMagick can read, so redirect the stdout to a file, say output.pnm






{kind=link}
{kind=link}
{kind=link}
{kind=link}